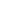Commercial insurance underwriting involves extracting risk related information from numerous documents and complex application data post submission. One of the primary challenges faced by insurers is the way in which the application submission data is captured and processed. A large volume of documents requiring evaluation is submitted by agents, brokers or through the portals. Relevant information is extracted and processed in a form that helps underwriters perform risk profiling and assessment. The back office has a team of manual indexers (underwriting assistants) who read through these documents to identify the intent of submission, sort the submission type, classify the document type, and then capture the required risk parameters for underwriting. This entire process if done manually is cumbersome, has a slow turnaround time and is error prone. It also requires additional manual indexers to address peak loads and often, not all required data is captured. As a result, there is a considerable impact on the quality of underwriting.
To address these challenges, carriers have started using optical character recognition (OCR) technology-based solutions to automatically extract data from documents. However, carriers have not been able to realise the true benefits of this automation as the extraction efficiency and accuracy metrics are still low and mostly require a high human-in-the-loop intervention. The reasons being:
- The data needed for most processes exists in various document types and file formats which are primarily unstructured. While the structured data extraction efficiency from structured forms like ACORD is good, the same cannot be said for semi-structured or unstructured documents like loss runs, broker specification documents and schedule of values.
- Data is typically submitted in different file formats through multiple channels, such as emails, attachments, online portals, contact centre calls, internal phone calls, and faxes.
- Data submitted through these multiple channels needs to be appropriately collated, contextualized and digitized with a high degree of accuracy.
- Submissions are often incomplete and key information is missing in the documents.
- An additional complication is that the submitted documents often include handwritten information, which becomes difficult to extract.
While OCR capabilities are effective to some extent, those need to be augmented with artificial intelligence or machine learning (AI/ML) driven document processing and robotic process automation (RPA) capabilities to maximize the efficiency of data extraction and subsequently the underwriting process. This can be achieved in a two-step process as stated below.
Stage 1: To implement an intelligent document processing solution:
The traditional optical character recognition (OCR) solution approach includes data-based search for keywords, phrases, patterns, or graphical features on the document. However, as the number and complexity of document types increase, rules become difficult to configure and expensive to maintain.
In contrast, an intelligent document processing solution uses AI technology such as natural language processing (NLP), computer vision, deep learning, and ML to automatically classify, categorize, and extract relevant information from a vast collection of unstructured document formats.
The “learn by example” technique (machine learning) automatically learns the key features of each document type through a training process which involves gathering samples and ‘showing’ the system which documents fall into which class. Once the key features have been learned for a sufficiently broad set of documents, previously unclassified documents can be auto classified, separated, and extracted by a higher degree of accuracy. The critical aspect here is the “training” and “learning” part of the model build. The corpus of documents utilized for model training should be with considerable volume and complexity to ensure that the variance across formats is minimal. There must be a feedback mechanism in place for the supervised learning to assess the correctness of the classification that can help provide valuable inputs for model re-training.
Stage 2: Combining document processing with RPA:
The next step is to integrate with surround systems using a RPA solution, to eliminate the manual processing of submissions and other associated processes. This will enable a no-touch or low-touch submission intake process for underwriting. Embedding intelligent document processing within the RPA platform is what enables business users to automate processes end to end. When intelligent document processing and RPA are leveraged together, the underwriters derive the best possible output for efficient underwriting.
Our Recommendations:
- Choose the right automation solution with cognitive capabilities:
It is important to first assess the automation maturity with respect to the business problem at hand and then choose the appropriate solution. As each solution has its own strength and limitations. As far as the commercial insurance intake process is concerned, there are matured solutions available in the market for structured data extraction as compared to unstructured data like loss runs and broker specification document.
- Supervise machine learning:
Given the maturity and efficiency of the currently available technology options, there is a need for certain level of manual intervention or Human-in-the-Loop supervision. The more time we spend training the system, the more is the extraction accuracy. Hence it is very important to ensure that the training data sets are comprehensive and of the right size. Supervised learning, over time, enhances the efficiency of data extraction and processing to the desired levels.
- Set the right expectation :
Cognitive machine learning solutions mature through numerous trials and are iteratively fine-tuned. Given that intelligent document management evolves over a period to mature and deliver the desired levels of efficiency, stakeholders need to be aware that full automation can be achieved in a phased manner and essentially is not a one step process.
- Get business buy-in:
It is also important to secure a buy in from the business stakeholders up front, after providing them a clear understanding of the benefits and challenges associated with the model build. Business and IT must collaborate closely to constantly review the outcome at each phase, make necessary course corrections and take responsibility for the results of the projects.
The Tech Mahindra Edge
Tech Mahindra brings together the right set of partner solutions and in-house advanced data analytics capabilities to digitalise commercial insurance underwriting journey for insurers globally and reduce the time it takes to complete the underwriting journey by 80%.
To learn more about our insurance capabilities, visit https://www.techmahindra.com/en-in/insurance/
About the Author
Arun John,
Principal Consultant – Insurance at Tech Mahindra
Arun is an insurance subject matter expert representing insurance Competency team of Tech Mahindra. Arun brings with him 18 years of experience in Property & Casualty (P&C) insurance domain which includes product management, insurance operations, delivery management, pre-sales and thought leadership. During his career in mainstream insurance and IT, he has worked on core policy administration systems, digital automation solutions and portals across multiple geographies.